※この記事は公開されてから1年半以上経過しています。情報が古い可能性がありますのでご注意ください。
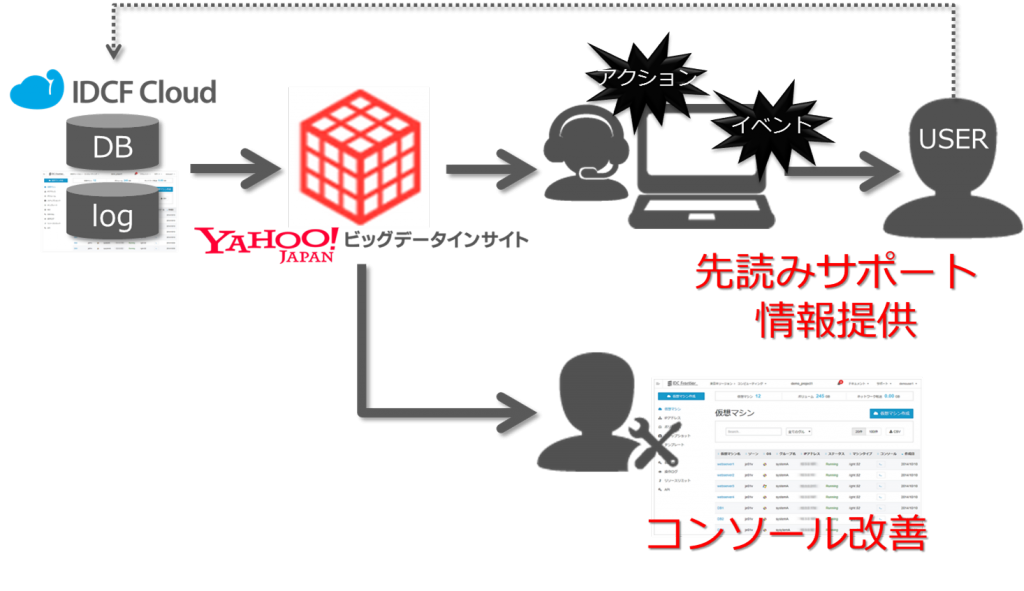
本日2014年9月25日 10時にYahoo!ビッグデータインサイトがリリースされました! やっとリリースできました。。。私自身は今年の4月からこのサービスに関わっていますが、長い人は1年以上このサービスに関わっている人もいてなかなか感慨深げでした。
さてリリースされた嬉しさもあり、初めてのエンジニアブログを書くこととなりました。
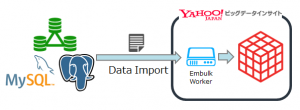
今回はYahoo!ビッグデータインサイトへの初めてのエントリーですので、簡単なサービス概要と簡単な使い方としてWebサーバーであるNginxのログデータをtd-agent経由でYahoo!ビッグデータインサイトに放りこむ手順をご紹介します。
Yahoo!ビッグデータインサイトに記載があるように、すぐにアカウント登録でき簡単に使い始められることを実感していただけると思います。
Yahoo!ビッグデータインサイトとは
サービスページに色々書かれていると思いますが、個人的には以下だと思っています。
- 大容量データを貯めるための箱
- 大容量データを効率的に分析するための基盤
- 分析対象データのアップロード、分析結果のアウトプットを補助してくれるツールが豊富なサービス
Visualization機能は提供しておりませんが、Visualization以外のデータ分析の機能を提供してくれるサービスだと思っています。
今回やること
IDCフロンティアが提供するセルフクラウドで作成したVM(Ubuntu 12.04)上のWebサーバー(Nginx 1.1.19)のログをtd-agent経由でYahoo!ビッグデータインサイトにアップロードさせてみます。
セルフクラウドのVMでなければ動作しない手順でもないと思うので是非皆様の環境でお試しください。 それでは始めてみましょう。
注:ここではNginxがインストールされていることを前提とします。
SingUp
SignUpがまだの方はSignUpページで必要事項を入力しサインアップをしてください。
迷うことはあまりないかもしれませんが、手順書も用意しているのでよければ参照してください。 
CLIのインストール
コマンドラインで作業をした方が楽なので、Yahoo!ビッグデータインサイトのCLI(Command Line Interface)をインストールします。 Nginxを入れているサーバーに入れる必要はありませんが、ここでは同じサーバーにインストールします。 まずは以下のコマンドRubyGemsをインストールします。
$ sudo apt-get install rubygems
CentOSの場合は以下のコマンドでインストールします。
$ sudo yum install rubygems
以下のコマンドでgemでCLIツールをインストールします。
$ sudo gem install td
td-agentのインストール
Nginxをインストールしているサーバーにログインします。 td-agentは以下のコマンドでインストールすることができます。
$ curl -L http://ybi-toolbelt.idcfcloud.com/sh/install-ubuntu-precise.sh | sh $ sudo td-agent --version td-agent 0.10.50
お使いの環境がCentOSの場合は以下のコマンドでtd-agentをインストールすることができます。
$ curl -L http://ybi-toolbelt.idcfcloud.com/sh/install-redhat.sh | sh
API-Keyの取得
td-agent経由でYahoo!ビッグデータインサイトにデータをアップロードするためにはAPI-Keyが必要となります。
API-Key取得のためには、まずは先ほどサインアップしてもらったアカウントでWebConsoleでサインインします。
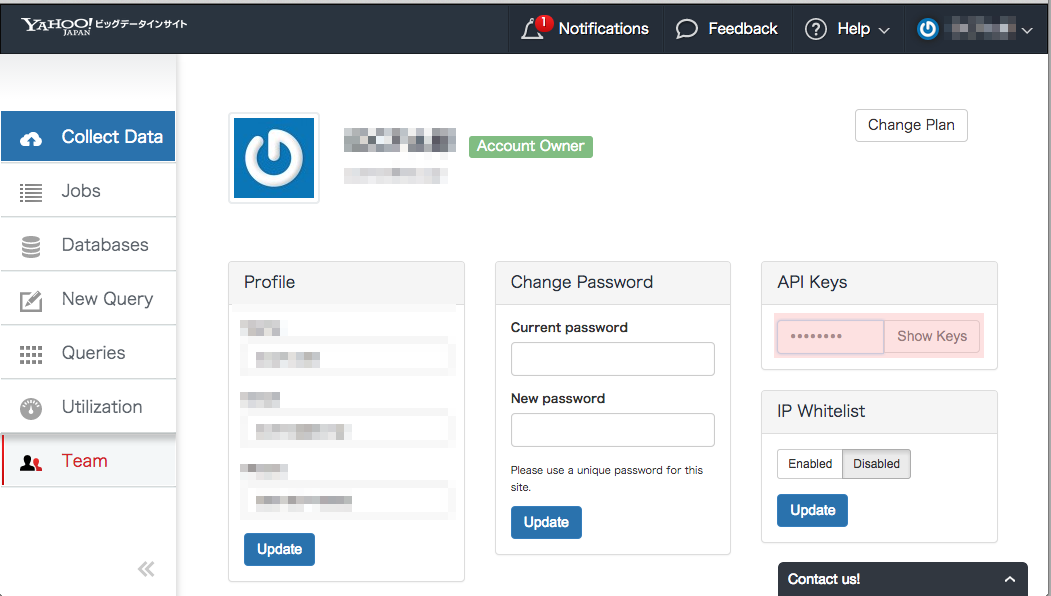
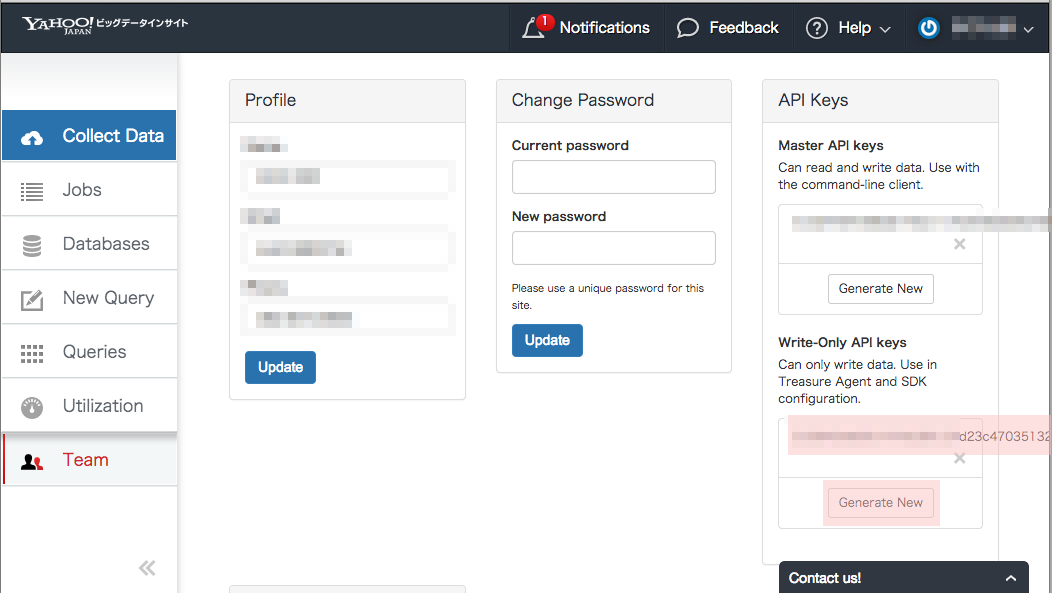
SignIn後にWebConsoleの画面上部右のAccount > My Profile をクリックし、Profile画面を表示させます。
API Keysパネルでパスワードを入力して、Show KeysボタンをクリックすることでAPI-Keyが取得できます。
アップロード先DBの作成
Nginxのログデータを格納するDBを作成します。
まずはCLIをインストールしたサーバーで以下のコマンドを実行し、Yahoo!ビッグデータインサイトにログインします。
$ td -e http://ybi.jp-east.idcfcloud.com account -f your_email_address@example.com Enter your Treasure Data credentials. Password (typing will be hidden): Authenticated successfully. Use 'td -e http://ybi.jp-east.idcfcloud.com db:create <db_name>' to create a database. $
次に以下のコマンドでDBを作成します
$ td -e http://ybi.jp-east.idcfcloud.com db:create nginx
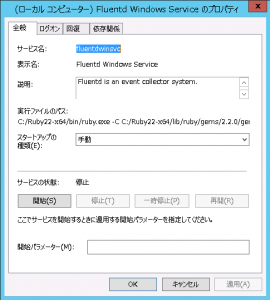
td-agentの設定
td-agentをインストールしたサーバーにログインし、以下のように設定ファイル(/etc/td-agent/td-agent.conf)を編集します。
# Tailing the Nginx Log<source> type tail path /var/log/nginx/access.log pos_file /var/log/td-agent/nginx-access.pos tag td.nginx.access format nginx</source> # Treasure Data Input and Output<match td.*.*>
type tdlog
apikey ${your_api_key}
auto_create_table
buffer_type
file buffer_path /var/log/td-agent/buffer/td
endpoint http://ybi.jp-east.idcfcloud.com
flush_interval 10s
use_ssl true
</match>
上記のざっくりした意味ですが、
- source type: tailを指定して新規で追加されたログを取得することを指定してます。
- source path: 監視対象のパス
- source tag: 監視対象のtag付けをして以降で設定しているmatchの処理を行うようにしている。td.nginx.accessはYahoo!ビッグデータインサイト上のnginxというDBのaccessというテーブルにデータを登録するような指定をしています。
- flush_interval: ログデータの送出間隔を指定しています。
となります。 以上でログをアップロードさせる準備は整いました!
データアップロードの確認
さてここからが本番・・・と言いつつ準備が長くてこちらの方が文章的には短いのですが。。。
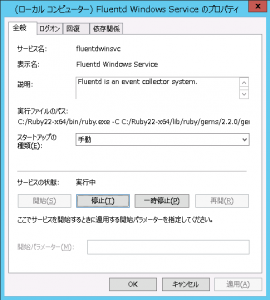
まずはNginxを起動します。
$ sudo service nginx start
次にtd-agentを起動します。
$ sudo /etc/init.d/td-agent start
次に確認のためにcurlコマンドでNginxサーバーにアクセスしてみます。 念のため5回アクセスします。
$ curl http://localhost $ curl http://localhost $ curl http://localhost $ curl http://localhost $ curl http://localhost $ sleep 10
Nginxのログは以下のように出力されます。
$ sudo cat /var/log/nginx/access.log 127.0.0.1 - - [14/Aug/2014:01:26:09 +0900] "GET / HTTP/1.1" 404 169 "-""curl/7.22.0 (x86_64-pc-linux-gnu) libcurl/7.22.0 OpenSSL/1.0.1 zlib/1.2.3.4 libidn/1.23 librtmp/2.3" 127.0.0.1 - - [14/Aug/2014:01:26:11 +0900] "GET / HTTP/1.1" 404 169 "-""curl/7.22.0 (x86_64-pc-linux-gnu) libcurl/7.22.0 OpenSSL/1.0.1 zlib/1.2.3.4 libidn/1.23 librtmp/2.3" 127.0.0.1 - - [14/Aug/2014:01:26:12 +0900] "GET / HTTP/1.1" 404 169 "-""curl/7.22.0 (x86_64-pc-linux-gnu) libcurl/7.22.0 OpenSSL/1.0.1 zlib/1.2.3.4 libidn/1.23 librtmp/2.3" 127.0.0.1 - - [14/Aug/2014:01:26:12 +0900] "GET / HTTP/1.1" 404 169 "-""curl/7.22.0 (x86_64-pc-linux-gnu) libcurl/7.22.0 OpenSSL/1.0.1 zlib/1.2.3.4 libidn/1.23 librtmp/2.3" 127.0.0.1 - - [14/Aug/2014:01:26:13 +0900] "GET / HTTP/1.1" 404 169 "-""curl/7.22.0 (x86_64-pc-linux-gnu) libcurl/7.22.0 OpenSSL/1.0.1 zlib/1.2.3.4 libidn/1.23 librtmp/2.3"
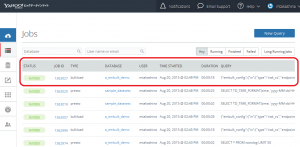
さていよいよYahoo!ビッグデータインサイトにデータが含まれているかを確認します。 CLIを利用して以下のコマンドでnginx.accessのデータ件数を確認します。
$ td table:list nginx +----------+--------+------+-------+--------+---------------------------+---------------------------+-----------------------------------------------------------------------------------------------------------------------------+ | Database | Table | Type | Count | Size | Last import | Last log timestamp | Schema | +----------+--------+------+-------+--------+---------------------------+---------------------------+-----------------------------------------------------------------------------------------------------------------------------+ | nginx | access | log | 5 | 0.0 GB | 2014-08-14 01:26:13 +0900 | 2014-08-14 01:26:13 +0900 | host:string, path:string, method:string, referer:string, code:string, remote:string, agent:string, user:string, size:string | +----------+--------+------+-------+--------+---------------------------+---------------------------+-----------------------------------------------------------------------------------------------------------------------------+
データが5件入っていることがわかるかと思います。 内容も確認してみます。
$ td query -w -t hive -d nginx "SELECT * FROM access"
+------+------+--------+---------+------+-----------+-----------------------------------------------------------------------------------------------------+------+------+--------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+------------+
| host | path | method | referer | code | remote | agent | user | size | v | time |
+------+------+--------+---------+------+-----------+-----------------------------------------------------------------------------------------------------+------+------+--------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+------------+
| - | / | GET | - | 404 | 127.0.0.1 | curl/7.22.0 (x86_64-pc-linux-gnu) libcurl/7.22.0 OpenSSL/1.0.1 zlib/1.2.3.4 libidn/1.23 librtmp/2.3 | - | 169 | {"host":"-","user":"-","path":"/","referer":"-","method":"GET","code":"404","size":"169","time":"1407947169","remote":"127.0.0.1","agent":"curl/7.22.0 (x86_64-pc-linux-gnu) libcurl/7.22.0 OpenSSL/1.0.1 zlib/1.2.3.4 libidn/1.23 librtmp/2.3"} | 1407947169 |
| - | / | GET | - | 404 | 127.0.0.1 | curl/7.22.0 (x86_64-pc-linux-gnu) libcurl/7.22.0 OpenSSL/1.0.1 zlib/1.2.3.4 libidn/1.23 librtmp/2.3 | - | 169 | {"host":"-","user":"-","path":"/","referer":"-","method":"GET","code":"404","size":"169","remote":"127.0.0.1","time":"1407947171","agent":"curl/7.22.0 (x86_64-pc-linux-gnu) libcurl/7.22.0 OpenSSL/1.0.1 zlib/1.2.3.4 libidn/1.23 librtmp/2.3"} | 1407947171 |
| - | / | GET | - | 404 | 127.0.0.1 | curl/7.22.0 (x86_64-pc-linux-gnu) libcurl/7.22.0 OpenSSL/1.0.1 zlib/1.2.3.4 libidn/1.23 librtmp/2.3 | - | 169 | {"host":"-","user":"-","path":"/","referer":"-","method":"GET","code":"404","size":"169","remote":"127.0.0.1","time":"1407947172","agent":"curl/7.22.0 (x86_64-pc-linux-gnu) libcurl/7.22.0 OpenSSL/1.0.1 zlib/1.2.3.4 libidn/1.23 librtmp/2.3"} | 1407947172 |
| - | / | GET | - | 404 | 127.0.0.1 | curl/7.22.0 (x86_64-pc-linux-gnu) libcurl/7.22.0 OpenSSL/1.0.1 zlib/1.2.3.4 libidn/1.23 librtmp/2.3 | - | 169 | {"host":"-","user":"-","path":"/","referer":"-","method":"GET","code":"404","size":"169","remote":"127.0.0.1","time":"1407947172","agent":"curl/7.22.0 (x86_64-pc-linux-gnu) libcurl/7.22.0 OpenSSL/1.0.1 zlib/1.2.3.4 libidn/1.23 librtmp/2.3"} | 1407947172 |
| - | / | GET | - | 404 | 127.0.0.1 | curl/7.22.0 (x86_64-pc-linux-gnu) libcurl/7.22.0 OpenSSL/1.0.1 zlib/1.2.3.4 libidn/1.23 librtmp/2.3 | - | 169 | {"host":"-","user":"-","path":"/","referer":"-","method":"GET","code":"404","size":"169","remote":"127.0.0.1","time":"1407947173","agent":"curl/7.22.0 (x86_64-pc-linux-gnu) libcurl/7.22.0 OpenSSL/1.0.1 zlib/1.2.3.4 libidn/1.23 librtmp/2.3"} | 1407947173 |
+------+------+--------+---------+------+-----------+-----------------------------------------------------------------------------------------------------+------+------+--------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+------------+
5 rows in set正しくデータが入っていることがわかるかと思います。
おわりに
いかがでしたでしょうか。 Yahoo!ビッグデータインサイトのサインアップからNginxのログをアップロードするまでを説明しましたが、簡単でしたでしょうか。 このコンテンツを作るには思いのほか時間がかかった(3hぐらいorz)のですが、作業自体は簡単にできたと思います。
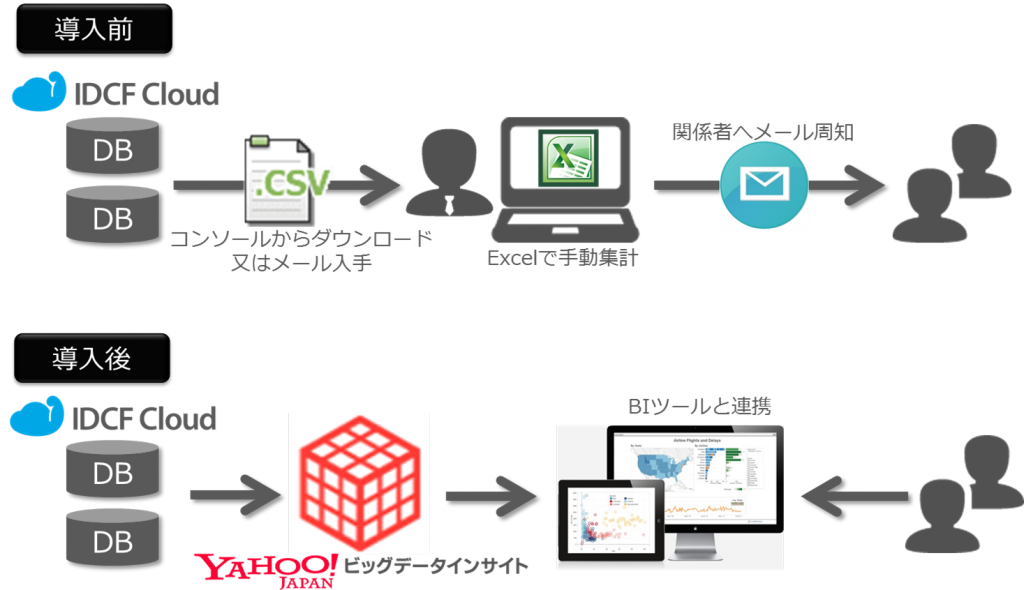
今回はNginxのログをYahoo!ビッグデータインサイトにアップロードする手順を説明させてもらいましたが、もちろん独自アプリケーションログをアップロードすることもできますし、最近TreasureData社では各種SDKの開発に力を入れており、Javascript SDK、Android SDKなどを用いることでユーザの操作ログを取得することも可能です。
また解析結果の出力機能も充実しており、最近ではTableauに出力させることもできますし、Google SperadSheet、さらにオブジェクトストレージにも出力させることができます。
是非Yahoo!ビッグデータインサイトを試してみてください!利用は無料なのでw 長くなってきたので、このへんで。